Part-1:- Convolutional Neural Network in a Nutshell

CNN is emerging in recent years as the most famous strain of neural networks research. They have revolutionized computer vision and achieved state-of-the-art results in many tasks. Some of their applications are image classification, detecting and labeling objects, support autonomous vehicles navigation system, face recognition, etc. In this blog post, we will cover,
Part 1- CNN in a nutshell
- Why CNN is successful in the image classification task
- What are some fundamental building block of CNN
- How these building blocks come together to build CNN architecture
Part 2 — CNN Keras Implementation
- CNN implementation in Python using Keras deep learning library
- Coding — step by step guide and explanation
- Data preparation — data resizing, augmentation and train, validation & test split
- CNN architecture construction using Keras library
- model training and testing
- output visualization
The reason why CNN is best at image classification
Convolutional Neural Networks (CNNs) is a particular type of neural network inspired by animal visual cortex perception system and mimicked it for computer vision applications. I will try to discuss only the unique characteristics of CNN compared to other Neural Network types. In my opinion there are two fundmental chracterstics of CNN that makes it best at image classificaiton
- Capability to extract positional(spatial) relationship in the image and create several feature map abstraction layer
- Fewer parameters to learn compared to a Fully connected neural network, that gives faster training time and less computational cost
- One of the unique characteristics of CNN is it assumes that there is a sense of locality, where inputs that are close to each other (pixels in the image) are related, whereas inputs that are further away are less related. In images, this makes sense since we normally have patches of similar color, lighting, and texture.
This CNN ability CNN enables it to capture the spatial relationship in the image. For example, to recognize the below image as a human face the positional arrangement of each pixel is important. Pixels near each other combined together to form something like eyes, nose, lips, ears, hair, etc. So, to easily recognize the picture it is better to take nearby pixels together (to extract spatial information of pixels).

However, if we use the fully connected neural network, we have to unroll the image so that we will get one column vector of data. I guess you all know that image is represented in number into a computer. Thus, the image is unrolled we lose all the important spatial information of the parts in the image. This is one of the major reason that this kind of network is not preferred for image classification.
2. Another problem in a fully connected neural network for image classification is the number of parameters, let’s say the image is 1 megapixel which means it has 1000x1000 pixels. Then the first input layer of the network will have 10⁶ neurons. If we use the same number of neurons in the second layer as the first layer, then the weight and bias at the input layer would be 10¹². If we have multiple hidden layers the parameters would be out of control or extremely computationally expensive. Thus, the problem of losing spatial information in an image and an extreme number of parameters makes a fully connected neural network bad option for image classification.

Basic CNN
The term convolution refers to the mathematical combination of two functions to produce a third function. It merges two sets of information.
In the case of a CNN, the convolution is performed on the input data with the use of filter or kernel to then produce feature maps. This kernel takes nearby pixels together which is important to extract positional relationship in the image data. Convolution is executed by sliding the filter/kernel over the input. At every location, matrix multiplication is performed and sums the result onto the feature map. It is like a torchlight moving over the image, and multiply the part of the image under the torchlight with the weights in the kernel.

In other words, what happens is this: the kernel is moving in over the input, from left to right and from top to bottom, and each one of the values on the kernel is multiplied by the value on the input on the identical place. The results collected by the multiplication are then summed and the local output is generated. Then this output pass-through activation function like RELU, sigmoid or tanh, RELU is the most widely used one.

As shown in the above figure, multiple kernels with the same dimension is used to extract different features embedded in the image. Thus the convolution step output will be feature maps that are the result of different kernel multiplied with the input image.
As shown below if it is a 3D image we will have RGB then it will be 3 dimensional, but the same principle applied.


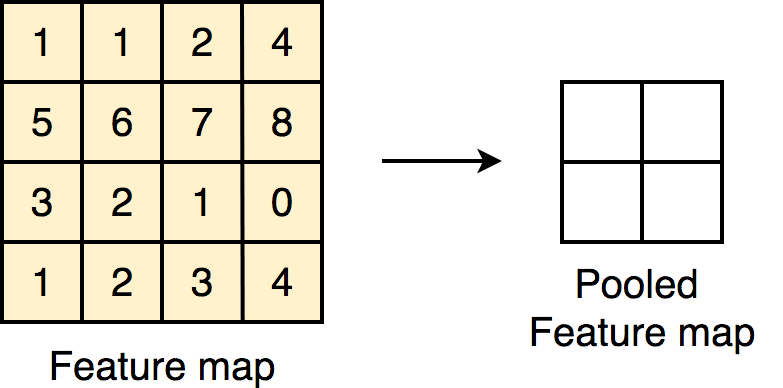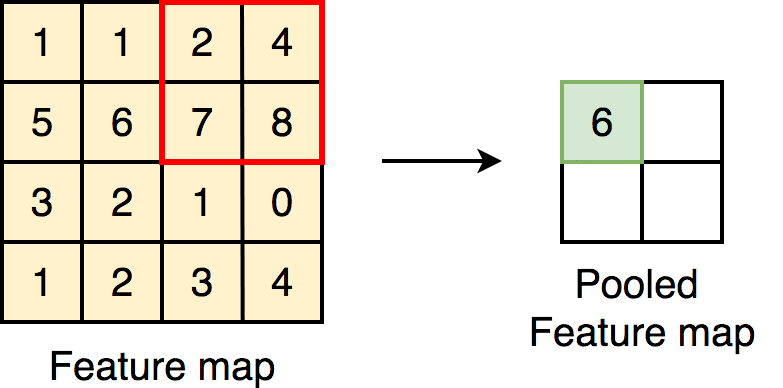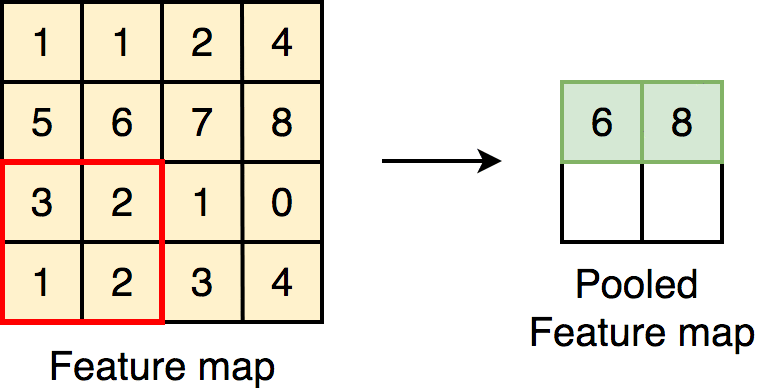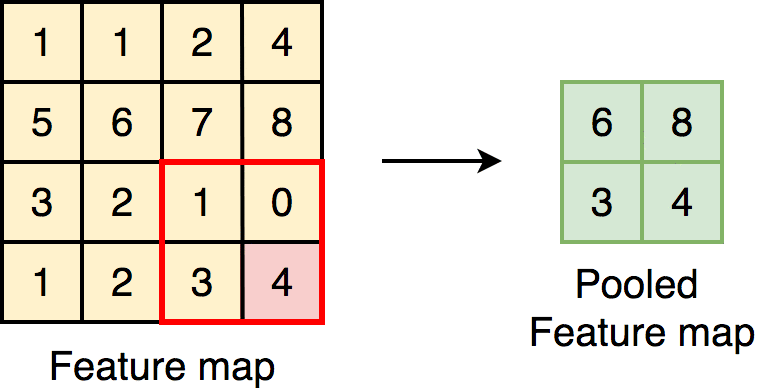
Max Pooling
After feature mapping, max pooling will follow up, which is a down-sampling of the feature map representation reducing its dimensionality. The working principle is the maximum number will be chosen out of the number fallen in the given kernel size. There are other pooling techniques like average pooling, but the most widely used one is max pooling.

These layers come together and joined to form the feature learning part of the CNN architecture. As shown in the image, each feature map passes through non-linear activation function like RELU, sigmoid before they pooling applied.

Finally, the feature maps will be unrolled/flatten into a single column vector to form a fully connected layer. This is important to bring down the 3D feature map into a number of classes we have in the problem, finally, the network can predict the right class out of the given classes.
Building CNN classifier Using Keras
Let's get into implementing the CNN model using python and Keras library that can predict how many fingers are shown in the image. I used Keras to build the CNN, and don’t worry if you don’t have experience with Keras or machine learning, through this guide you should get a pretty good understanding of how it works and its implementation.

{kind=link}